Recently Blog Entries
- Why Your Kanban Workflow Should Be More Than “In Progress”
- Two Questions to Help You Understand if You’re Doing Kanban
- Spike Abuse
- My Latest Article on Agile and Security
- Essentials of the Scaled Agile Framework
- A Possible Solution to the Issue of Test Data
- Project Sauron: A Long-lived, Stealthy and Likely State-sponsored Malware
- CCTV cameras used in massive botnet
- Sprint Planning: The Case for Finishing What You Start
- Scrum Retrospectives: Start, Stop… Continue? One of these things is not like the others…
Subscribe

Categories
Polls
 Loading ...
Loading ...
Archives
- May 2017
- April 2017
- September 2016
- August 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- December 2015
- October 2015
- September 2015
- July 2014
- January 2014
- March 2013
- February 2013
- January 2013
- December 2012
- July 2012
- May 2012
- April 2012
- January 2012
- November 2011
- October 2011
- September 2011
- August 2011
- April 2011
- October 2010
- August 2010
- July 2010
- June 2010
- May 2010
- March 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- February 2009
- December 2008
- November 2008
- September 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
Admin
Search
Mar
26
Paper Enigma
March 26, 2008 | Leave a Comment
During World War II, the Germans widely used several variants of the Enigma machine, which was actually created by a Polish inventor. This same Polish inventor helped the British with their famous project to crack the Enigma, and run by Alan Turing and centered at Bletchley Park.
The basic theory of the Enigma was that you had a number of wheels that had contacts on each side. If you picture a donut, think of sprinkles on both sides and you’ve got the basic idea. Now, if you connect a sprinkle on one side with a sprinkle on the other, but don’t go straight through the donut, you get a degree of obfuscation.
Stack three donuts side by side. The analogy goes a bit awry here, because imagine that we assign each of the sprinkles on each side a letter or number. We pick the letter we want to encode on the left donut, and then run a current through that sprinkle, and you get a current coming out in a pseudo-unpredictable sprinkle on the donut on the right, corresponding to the encoded letter or number. Each time you do encode a character, you rotate the donuts one step. The outer donuts you rotate towards you, and the inner one away. Now run the next current through. That’s how an Enigma works. Here’s an exploded view of an Enigma machine rotor, created by Wapcaplet in Blender.
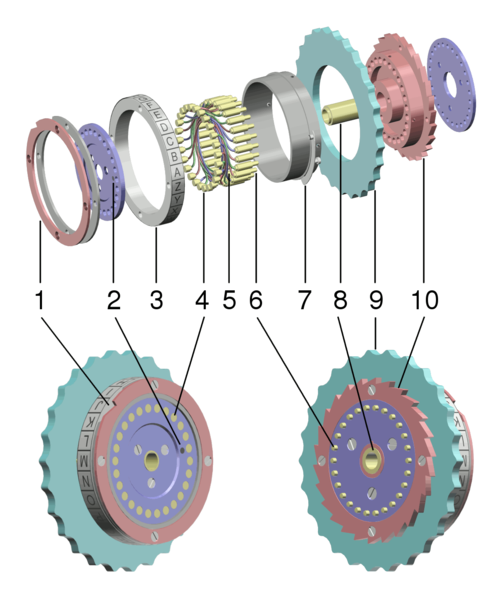
Later versions of the Enigma added a fourth rotor, and some used reflection, which ran the signal back through the rotors once it reached the right hand side.
If you want to try your hand at an Enigma, and don’t want to machine one yourself, Mike Koss has created a nifty paper Enigma for you to try.
Mar
25
The Development Methodology Lifecycle
March 25, 2008 | Leave a Comment
I’ve been thinking lately that software development methodologies are a funny thing. In some ways, their lifecycle mirrors the very software that they produce.
There’s a phenomenon where software gathers entropy over time, sometimes called “bit rot”. Bit rot requires you to refactor your software occasionally, even regularly, tuning it up and keeping it working at its best. Without this sort of maintenance, your software has a decreased lifespan. Many refactorings focus on making things simpler, easier to understand.
As with the software that comes out of a development methodology, the methodologies themselves start out all lean and efficient, as a kernel of good ideas. Sometimes the newborn methodology is inspired by what some other methodology is perceived as doing wrong. Over time, methodologies seem to accrete all sorts of things. These are good ideas, typically, special approaches to problems, or things that people find as complimentary practices. The problem is that these become enshrined in the canon, as it were. People who have less attention to what the methodology actually says about when to use these tools, or who have less experience and can’t understand when a tool applies, begin to apply all the tools, all the time. As a result, methodologies get rather bloated, become inflexible, and eventually fall out of favor because they become too unwieldy, or at least that’s the perception people have about methodologies. I think it’s because practitioners don’t really understand when to apply the tools in question.
Mar
18
RIP, Arthur C. Clarke
March 18, 2008 | Leave a Comment
A moment of silence, please, in memory of Arthur C. Clarke, science fiction author and visionary, reported dead today at 90. This weekend, good sir, I will raise a glass in your honor.
[via Engadget]
Mar
17
One of the most distressing things about being a security professional in today’s IT environment is what seems like a lax attitude towards securing customer information. All that could change if a ruling by the FTC against ValueClick, a spammer, stands up in court. In addition to settling with ValueClick regarding violations of the CAN-SPAM act, the FTC claims that ValueClick is also liable for not following their own advertised security policies.
“In the past, companies that failed to protect customer data have argued that they are immune from prosecution unless consumers can directly prove that they suffered harm from the breach of their personal information,” Kamber explains. “Given that hackers are generally pretty good at covering their tracks, this argument — if accepted — would mean that few companies would have to account for their negligence.”
quotes an article at Dark Reading. Kamber is Scott Kamber, a partner at Kamber Edelson LLC, a legal firm that specializes in cyber security law.
This would be a novel first, and a good one as well. To date, companies and other organizations that disclose their customers confidential information have been in for not much more than credit counseling and fraud monitoring on these customers behalf. This, frankly, is a slap on the wrist. Until organizations are held liable, in a significant way, for disclosing sensitive information, they will see little incentive for taking preventative measures.
For some context, in the last few years, hundreds of millions of people have had their confidential information disclosed to unauthorized parties. While it might prove burdensome for businesses to have to pay any sort of real damages when they fail to take adequate measures to protect confidential information, I believe that’s the only way to see that the necessary measures are actually taken, since it’s clear that the market can’t police itself.
Mar
13
RFID Dust for Tracking
March 13, 2008 | 2 Comments
The expanding use of RFID chips, and their ever-decreasing size, has led to what sounds like science fiction to me. A company called Nox Defense has created RFID tags so small that they are calling it “RFID dust”, and saying these tags can be scattered on the ground and then, per the original article on HelpNet:
People pick up the ID-Dust on their shoes, which covert RFID readers track, triggering video surveillance and alerting security personnel on hand-held devices. The Nox software creates a complete history of exactly where the person travels and when, and combines a facility map with real-time video surveillance.
It’s pretty incredible to me that we can now make these chips so small that they are 1) unnoticable and 2) small enough to stick to your shoes yet still have the ability to transmit radio signals any significant distance. Add to that doing so with any sort of encryption, which they also claim. I’d say it sounds like witchcraft, but the world moves on, and perhaps it’s true.
Years ago, Xerox developed active badges that would track your presence in the PARC as you moved around. Doors would unlock for you as you approached if you had access. The phones were also hooked into the system: if the phone rang, it was for someone in the room at the time.
So what’s the point of that story? The employees at Xerox were aware that they were being tracked, and being the type of people who worked at PARC, they had in some sense signed up for that sort of treatment. But even Xerox didn’t track you in the bathroom.
The creation of RFID tags that are now embedded in passports, computer equipment, and now even small enough to be scattered on the ground is enabling a culture of surveillance that’s deeply troubling to me. I don’t have enough faith left to believe that people won’t abuse that power, and the continuing abuse of National Surveillance Letters doesn’t do much to convince me that I’m being overly suspicious.
I don’t dispute that employers should be able to protect their equipment, that they should put up with employees stealing from them. This leaves me conflicted: I don’t support theft, I don’t support a culture of surveillance either. There has to be a way to balance these things out, but it’s gonna take someone smarter than me.
Mar
6
Models as Dictionaries
March 6, 2008 | Leave a Comment
Daniel and I got to talking again today about our favorite topic of late: what good are models in an agile environment? We reached some interesting conclusions.
We think that the process of developing a software system is in some ways inventing a new language. All the stakeholders, that is to say the developers, customers, and other interested parties, have to agree on their nouns and verbs, their common terms, which are the business concepts manipulated by the system. As we begin to identify a subset of those foundational concepts, we can they begin to form higher level constructs, such as sentences, descriptions of how the system behaves and manipulates those basic constructs. As these activities take place, the language is refined and expanded, new words are added to the vocabulary and new sentences are created, and it becomes easier and quicker to find ways to explain concepts and form yet more new sentences. This parallels nicely the way that real teams develop real systems, right down to the acceleration and growing shared understanding of the problem.
Now here’s where the modeling comes in. Just as with a natural language, we can make up our words in a meeting, and write them down on a white board, and erase them when we walk from the room, and that’s perfectly fine. We should realize that if we do that, we forgo the ability to let others learn the language as well, except from us. Further we are now required to remember the definition of every word and the nuances of every sentence. Most of us are pretty good at remembering words, but we still have dictionaries to help us out, so it’s a pretty good bet that a documented model would be useful as well.
Here’s where things start to get interesting. Companies themselves can also be modeled as systems, as can software development efforts. Development processes are also dictionaries of techniques for building software. To quote Daniel, who’s put it more succinctly than I could:
We can use the RUP (or another sufficiently-structured tome) as a dictionary to have a common language we can use to talk about how our processes are going (or not). Without that common language, it’s very hard for the team to communicate — it’s very hard for the organization to communicate to the team. It’s hard to have a discussion around what is working and what is not working. The RUP, in this case, is the common language that the industry has agreed upon that we can use to apply to create processes to solve our problems, just like we use the intermediate language with our customer to describe the problems that we can then apply solutions for. Just like the idea that we shouldn’t have a problem that our user brings us that we don’t have language for, we shouldn’t have problems with process in our software teams that we don’t have a way of describing. Not being able to describe problems in a common language prevents solutions from forming. I guess you could call it “Process Architecture”
When you think of a software development as a language, some other analogies jump out at you. Just as you wouldn’t try to write a novel using every possible word, you don’t want to use every tool and technique mentioned by every process for every project. You need to pick and choose the words and phrases (or tools and techniques) that are the correct ones to get your points across.
It’s a fairly robust analogy, I believe. I think chewing on this for a while may yield further insights for us.
Mar
6
A More Effective Java Coding Standard
March 6, 2008 | 2 Comments
Over the years, I’ve read a fair number of Java coding standards. Very few of them, I’m going to go so far as to say “none”, really talk about what they should. That’s a pretty bold statement, so let me explain.
Many coding standards for Java talk about low-value minutiae, things like “your variables should begin with a lower case letter, and be meaningful names”, and how you should place your parenthesis. I’d like a quarter for every 30 seconds that have been wasted talking about that last point. But I digress.
The things first-generation coding standards talk about are making our code “uniform” and “acceptable”, and have been beat to death. These are also largely things that can be handled very nicely with your modern day integrated development environments, thank you very much. Renaming a field takes almost no time at all, and I can set my IDE to reformat the parenthesis just how I like, or however the project dictates they should be formatted. These standards, while they create uniform looking code, have really very little return on the time you spend creating them. What we really needed today are some coding standards that talk about more valuable things, the things that are going to save us real time and prevent errors. Think of these as graduate level coding standards. Read more
Mar
5
Modeling and Agile Development
March 5, 2008 | Leave a Comment
Daniel has an interesting post on his site, What To Fix, regarding his thoughts on the role of modeling in an agile project. We’re working with some of the same people currently, so I have some insight into his points.
On one hand, people say its all emergent — put a bunch of really smart people in a room with the Product Owner and fixed time-boxes and the conversation and code will follow along naturally. I don’t think there is any denying that it’s a true statement that software can emerge from shared conversations about problems.
On the other hand, there’s the role of modeling in software development. Diagrams seem to help people understand and talk about things better, so couldn’t they be part of a conversation as well?
I’ve had some of the same misgivings, and the same thoughts. I think that modeling in an agile environment serves more than one master. First, it allows us to visually organize our thoughts. Visual models are a very information-rich way of communicating information, you can put a lot of details into diagrams if you know the language. They’re a very efficient way to communicate thoughts.
Mar
4
Compression Waves and Traffic
March 4, 2008 | 2 Comments
For quite a while, I’ve known that one of the most annoying aspects of traffic jams are the compression waves. With all the driving I’ve been doing lately, this has been on my mind. Compression waves in traffic occur when for some unknown reason, somebody has to break, then it cascades down the line, just like a slinky.
Well, according to an article on Slashdot, it turns out that this phenomenon is more than just an annoyance associated with traffic jams, it can cause them.
A team from Nagoya University in Japan had volunteers drive cars around a small circular track and monitored the way ‘shockwaves’ — caused when one driver brakes — are sent back to other cars, caused jams to occur.
This just reinforces that we really ought to get working on those smartcars, so the robots can save us from creating compression waves.
Mar
4
Using CPU Heat to Cool CPUs
March 4, 2008 | 1 Comment
I’ve been wading through tons of announcements of new cameras, cellphones and monitors of late, and very few things have grabbed my attention, but the idea of using the heat from a CPU to power a Sterling engine, which in turn powers a fan for the heat sync seems deliciously ironic.
Of course, as the fan cools the heatsink it deprives itself of energy, supposedly the piston affixed to the crankshaft pulls back down, giving it another potential surge when its heat rebuilds.
[via Engadget]
Blogroll
- Ars Technica
- Dark Reading - IT Security
- Help Net Security
- InformIT
- SANS Internet Storm Center
- Schneier on Security - Dr. Bruce Schieier’s blog
- Security Info Watch
- What to Fix - Daniel Markham, fellow consultant
- Wired Gadget Lab
- Wordpress Documentation
- WordPress Planet
- Wordpress Support Forum